
Old Reliable
Predictable, But Limited
- •Reactive helpdesk hours with unpredictable queues.
- •Tiered support teams that keep knowledge siloed.
- •Manual ticket handoffs that stretch resolution timelines.
- •Budget-heavy retention of outdated tooling.
Stop scaling people. Start scaling with a proven IT operating system.
Most growing firms believe they have two options:
Hire more internal IT.
Or move to a larger MSP.
Both approaches scale headcount.
Neither fixes the delivery model.
Headcount isn't the problem.
Structure is.
Large MSPs scale by building bigger service desks. More technicians. More queues. More layers of escalation.
It feels responsive — until it isn't. And your internal IT team ends up managing the vendor instead of leading technology. That's not co-managed. That's outsourced volume.
Your team gets a random tech every time.
Handoffs between Tier I, II, and III delay resolution.

A generic service desk with weak accountability.
Hiring more internal staff seems logical. But one or two additional hires don't create continuous coverage or cross-functional depth.
They create dependency. And dependency creates fragility. You need structure, embedded security discipline, and performance accountability.
Coverage gaps and key-person dependencies increase vulnerability.
Preventive maintenance turns into reactive cleanup.

Hiring more people doesn't fix the underlying delivery model.
Old Reliable vs High Performance
Predictable, But Limited

Built for Speed and Control
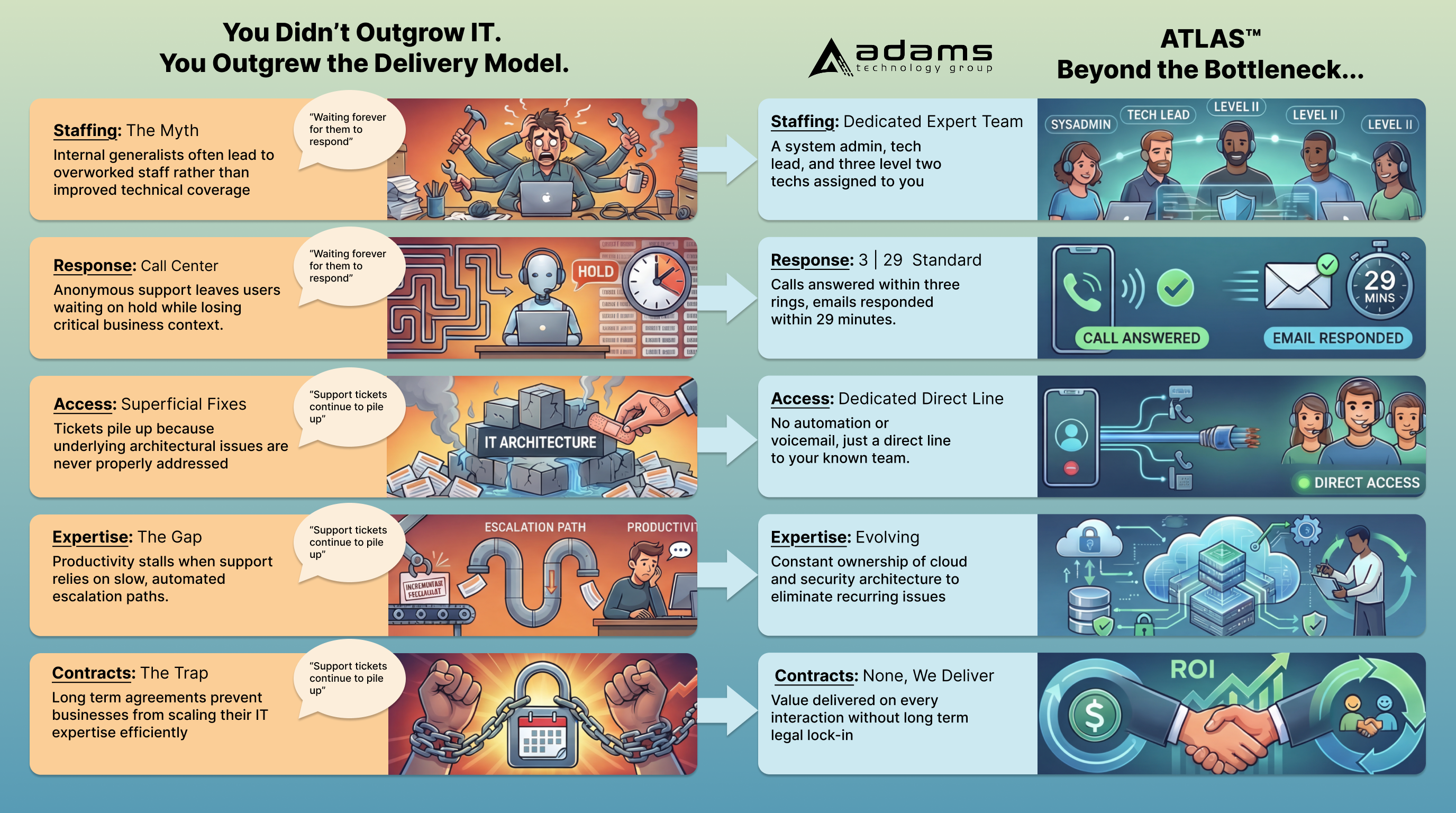
Traditional IT delivery models often fail as organizations scale. Internal generalists become overworked, and anonymous call centers leave users waiting on hold while losing critical business context.
The ATLAS™ framework provides a fundamentally different approach. We replace the traditional helpdesk with dedicated expert teams, rapid predictable response times under our 3|29™ Standard, and direct access—ensuring your underlying architecture evolves to eliminate recurring issues.
ATG Co-Managed IT Services operate on ATLAS — a structured IT operating system built for environments where incidents are inevitable and performance matters.
Continuous, measurable response under 3|29™.
Coordinated execution across network, systems, cloud, endpoint, and applications.
Defined accountability aligned directly with your IT leadership.
Standards, documentation, and lifecycle control — not tribal knowledge.
Operationally embedded security, not bolted on after the fact.
Every co-managed client is supported by a dedicated ATG Tech Ops Unit — a team of six technical professionals operating inside the ATLAS framework.
This is fundamentally different from a call center bench.
Six professionals.
Aligned.
Measured.
Industry-aware.
Your internal IT team integrates directly with this Unit.
A structured execution cell with clear ownership and performance accountability.
Schedule a consultation to determine whether ATLAS and a dedicated Tech Ops Unit are the right fit for your internal IT team.
Every Tech Ops Unit operates under our 3|29™ Performance Standard:
Every call answered within 3 rings.
Every ticket responded to within 29 minutes.
U.S.-based First Resolution Technicians.
Transparent dashboards and KPI reporting.
This isn't a marketing promise.
It's the operational baseline.
Large MSPs scale by adding technicians.
Internal IT scales by adding payroll.
ATG scales by adding structured Tech Ops Units inside ATLAS.
That's how performance stays predictable — even as demand increases.
